There are instances where you get a comma-separated list of keys in each row of a table, and you need to replace it with lookup values. This blog post shows two ways of addressing this situation in DAX. But first, why would you want to do it in DAX?
Why DAX?
Most people would likely say that the model is wrong and you should change it somehow so that each row contains one key only, which is probably what should happen in an ideal world. However, as Marco Russo says on Lars Schreiber’s SSBI-Podcast (around the 26:35 mark):
There is a market—there is a need of people who create short-term business intelligence models.
Side note: have you ever thought that Power BI podcasts would become a thing? Me neither, and yet it’s great that Lars started them!
There could be different justifications for “short-term business intelligence models”. For example, you could be simply exploring data and seeing whether it’s interesting. At the same time, you could be working with a painfully slow data source, so using DAX would be much quicker than Power Query.
In other words, it doesn’t always make sense to build a model perfectly: you should do the cost-benefit analysis. If you’re sure that the model will be there for a long time, then by all means you should do it “properly”. Sometimes that means using tools other than Power Query. In other cases, you just want to do things quickly so you can progress in your analysis further, so using DAX makes sense.
Therefore, I’ll show two ways of solving the problem of comma-separated values in DAX.
Sample data
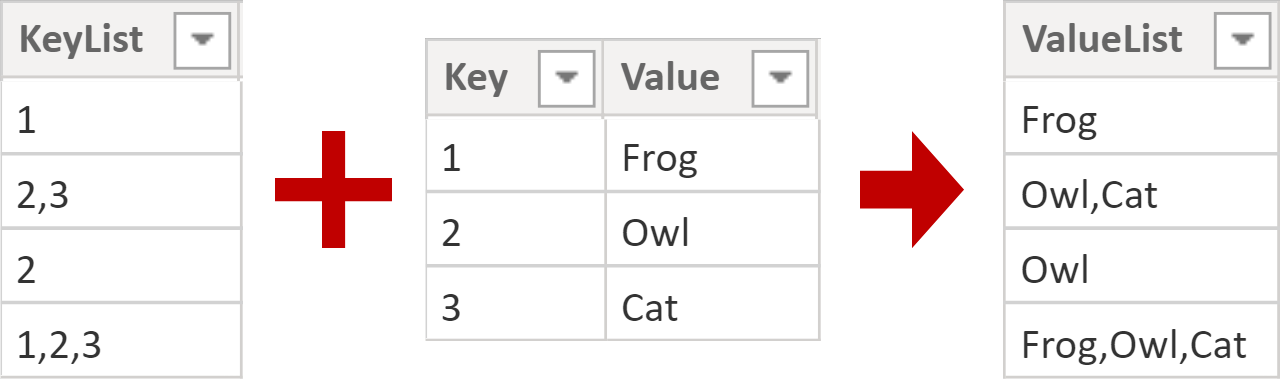
Let’s say we’re working with two tables:
- KeyList—contains comma-separated keys in the KeyList column.
- Key—is the lookup table with two columns: Key and Value.
You can see both of them in the top image in this blog post.
Method 1: calculated column
One way to address the issue is to create a calculated column. This one will do the trick:
ValueList =
VAR AsPath =
SUBSTITUTE(
KeyList[KeyList],
",",
"|"
)
VAR KeyPositions =
GENERATESERIES(
1,
PATHLENGTH(AsPath)
)
VAR LookupValues =
SELECTCOLUMNS(
KeyPositions,
"Value",
LOOKUPVALUE(
'Key'[Value],
'Key'[Key],
PATHITEM(AsPath, [Value])
)
)
VAR Result =
CONCATENATEX(
LookupValues,
[Value],
","
)
RETURN
ResultMost solutions have a secret sauce; in this case, it’s the creative use of the parent-child DAX functions 🙂 Here’s what the formula is doing for each row of the table:
- In the AsPath variable, we’re replacing commas with pipes. This is required for the PATH family of functions to work.
- In KeyPositions, we’re generating a virtual table that has the same number of rows as the number of keys the current row has.
- In the LookupValues, we’re doing a lookup for each individual key from KeyList by using the Key table. PATHITEM is responsible for retrieving each individual key from the list of keys.
- Finally, in the Result variable, we’re combining the lookup values.
Note that if you’ve got spaces after the separator or a different separator, you’ll need to account for it. TRIM can be helpful here.
Here’s the result:
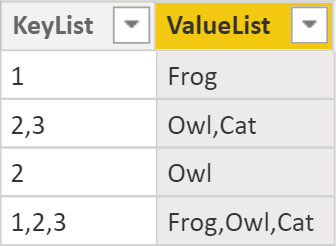
Depending on your business requirements, this may not be appropriate, especially if you want to filter the text values without using the “contains” logic. In this case, the next method might suit you better.
Method 2: bridge table
Another way of addressing the issue is to create a bridge table like so:
Bridge =
GENERATE(
DISTINCT(KeyList[KeyList]),
VAR AsPath =
SUBSTITUTE(
KeyList[KeyList],
",",
"|"
)
VAR KeyPositions =
GENERATESERIES(
1,
PATHLENGTH(AsPath)
)
VAR Result =
SELECTCOLUMNS(
KeyPositions,
"Key",
PATHITEM(AsPath, [Value])
)
RETURN
Result
)Since we’re now operating in filter context, we need to generate row context. We can do so by using GENERATE and iterating through distinct KeyList values. The AsPath and KeyPositions variables are the same as in the previous method. In the Result variable though, we’re effectively splitting the list into a table of values.
Here’s the result:
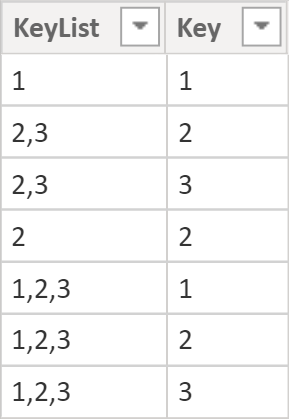
If you’re a purist and want Key to be integer, you can set the third parameter of PATHITEM to INTEGER.
Once you have this table, you can relate it to the KeyList and Key tables, so you can filter KeyList by Key like so:
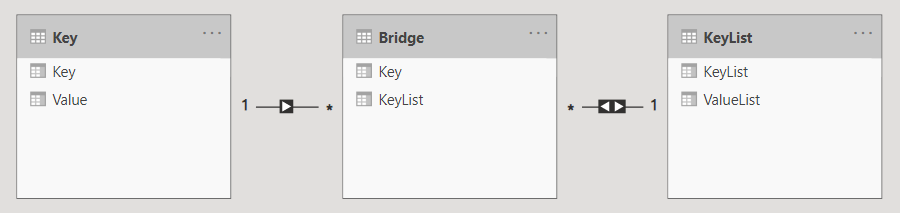
Note that it’s important to use DISTINCT or ALLNOBLANKROW in the bridge table because VALUES or ALL will result in the circular dependency error.
A curious reader might ask, “Why are you using the KeyList[KeyList] column? It’s text, isn’t it? Wouldn’t an integer key for the table compress better?” My answer is–maybe, it depends:
- If each row has lots of keys in the same row and there are lots of different combinations, making the cardinality similar to the table key, then probably using an integer key instead of KeyList[KeyList] would be better.
- If there are relatively few unique values in KeyList[KeyList] compared to the integer key, then you’ll probably be better off using KeyList[KeyList].
- There may not be a key for the table as fact tables should rarely have keys, for instance.
Whichever method you choose, happy CSV lookups! 🙂
Sample file: CSV DAX.pbix (33 KB)