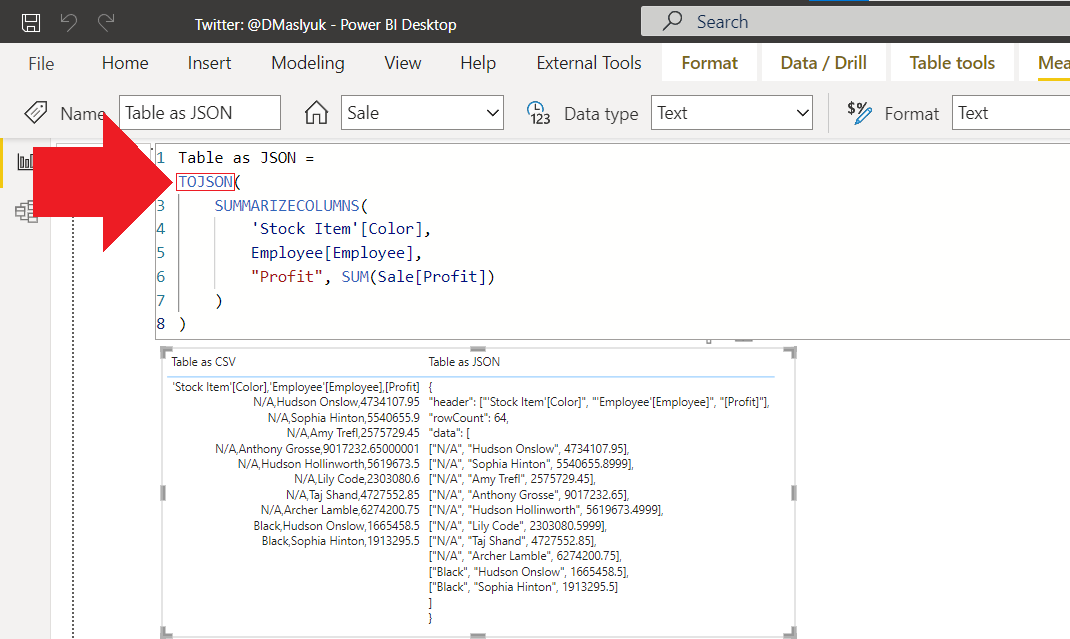
In October 2022, two new DAX functions appeared in the Power BI service: TOCSV and TOJSON. In this blog post, I’m showing a few use cases. Continue reading “New DAX functions: TOCSV and TOJSON”
More than Excel BI
In October 2022, two new DAX functions appeared in the Power BI service: TOCSV and TOJSON. In this blog post, I’m showing a few use cases. Continue reading “New DAX functions: TOCSV and TOJSON”
Some people say that naming is the hardest aspect in coding. Today’s blog post is about naming conventions. Continue reading “Power BI Antipatterns #13: Naming conventions”
If you’re accustomed to performing merges in Power Query, you probably know that M is case-sensitive by default. In M, values should match exactly for a merge to work unless you do a fuzzy merge. In this blog post, I’m discussing case sensitivity in data models. Continue reading “Power BI Antipatterns #12: Model case sensitivity”
Measures that return 0 may be undesirable in certain cases, like when 0 isn’t an interesting value and you’re only interested in non-zero values. In Power BI Antipatterns #7, we saw how you can show 0 instead of BLANK; this blog post shows a common (bad) way of hiding 0 and two better ways. Continue reading “Power BI Antipatterns #11: Hiding 0 in DAX”
Besides potential performance degradation, which we covered in the previous blog post, you should avoid filtering whole tables in DAX because sometimes you may get unexpected results. In this blog post, I’m showing one example. Continue reading “Power BI Antipatterns #10: Filtering whole tables, part II”
Whenever you can, you should avoid filtering whole tables in DAX–as opposed to columns–in DAX, because the performance may suffer, or you may get unexpected results, or both. In this blog post, we’re looking at the performance aspect. Continue reading “Power BI Antipatterns #9: Filtering whole tables, part I”
While unformatted DAX formulas may not affect the calculation speed, they can take a lot of time to read, and they can even hide errors just because the errors are hard to spot. Despite there being several ways to format your DAX code, I still see a lot of formulas that aren’t formatted. Continue reading “Power BI Antipatterns #8: Unformatted DAX”
If you want to return 0 instead of BLANK, do you need to check if the result is BLANK first? I’m covering this and a few related issues in this blog post. Continue reading “Power BI Antipatterns #7: ISBLANK”
What’s VALUE in DAX used for? Do we always need IF in case you want to output 1 and 0 instead of TRUE and FALSE? That’s what this blog post is about. Continue reading “Power BI Antipatterns #6: IF and VALUE”
Do you know what CALCULATE with just one argument does? In a measure? In a calculated column? This is the topic of this blog post. Continue reading “Power BI Antipatterns #5: CALCULATE”