If you’re accustomed to performing merges in Power Query, you probably know that M is case-sensitive by default. In M, values should match exactly for a merge to work unless you do a fuzzy merge. In this blog post, I’m discussing case sensitivity in data models.
Here’s the basic antipattern that I see from time to time:
ProductBKeyForJoin = UPPER('Product'[SKU])It’s a calculated column created specifically for a relationship by using the UPPER or LOWER functions in DAX. Why is this a bad pattern? Because relationships in Power BI aren’t case-sensitive. Therefore, you create a copy of a column and use precious resources for no good reason.
What’s more, when Power BI loads data, it’ll minimize the different cases. Here’s an illustration of what I mean — use the Enter data feature in Power Query and create the following table:
| Column1 |
| A |
| a |
If you enable column distribution in Power Query Editor, you’ll see that there are two distinct values:
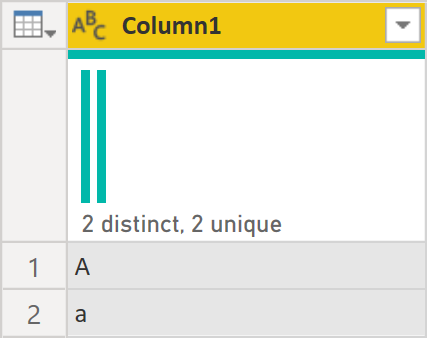
Note: what’s the difference between distinct and unique? Distinct is the number of different values; unique is the number of values that appear exactly once.
Once you’ll load this table, the Data view will show just one distinct value:
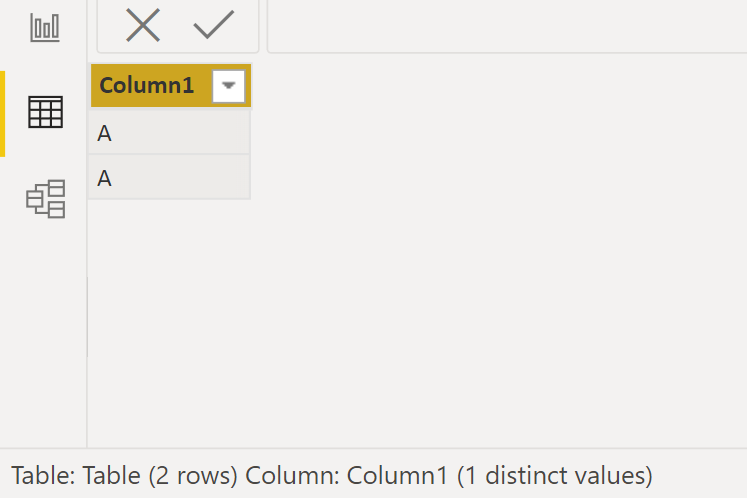
Again, relationships also won’t care about the case, as long as the values match, so no need to create copies of your columns with some consistent case.